Apache Spark has a colossal importance in the Big Data field and unless one is living under a rock, every Big Data professional might have used Spark for data processing. Spark may sometimes appear to be a beast that’s difficult to tame, in terms of configuration and tuning queries. Mistakes like long running operations, inefficient queries, high concurrency will individually or collectively affect the Spark job.
Before going further let’s go through some basic jargons of Spark:
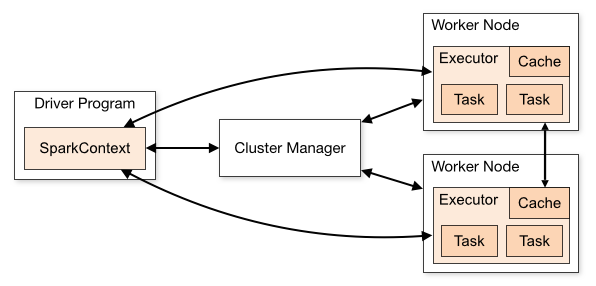
Executor: An executor is a single JVM process which is launched for an application on a worker node. Executor runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. A single node can run multiple executors, and executors for an application can span multiple worker nodes.
Task: A task is a unit of work that can be run on a partition of a distributed dataset, and gets executed on a single executor. The unit of parallel execution is at the task level. All the tasks within a single stage can be executed in parallel.
Partitions: A partition is a small chunk of a large distributed data set. Spark manages data using partitions that help parallelize data processing with minimal data shuffle across the executors.
Cores: A core is a basic computation unit of CPU and a CPU may have one or more cores to perform tasks at a given time. The more cores we have, the more work we can do. In Spark, this controls the number of parallel tasks an executor can run.
Cluster Manager: An external service for acquiring resources on cluster (e.g.
standalone manager, Mesos, YARN). Spark is agnostic to a cluster manager as long as it can acquire executor processes, and they can communicate.
Few steps to improve the efficiency of Spark Jobs:
Use the cache: Spark provides its own native caching mechanisms, which can be used through different methods such as .persist(), .cache(), and CACHE TABLE. This native caching is effective with small data sets as well as in ETL pipelines, where you need to cache intermediate results. However, Spark native caching currently does not work well with partitioning, since a cached table does not retain the partitioning data. A more generic and reliable caching technique is the storage layer caching.
Use memory efficiently: Spark operates by placing data in memory, so managing memory resources is a key aspect of optimizing the execution of Spark jobs. There are several techniques you can apply to use your cluster’s memory efficiently.
- Prefer smaller data partitions and account for data size, types, and distribution in your partitioning strategy.
- Consider the newer, more efficient Kryo data serialization, rather than the default Java serialization.
- Prefer using YARN, as it separates Spark-submit by batch.
To address ‘out of memory’ messages, try:
- Review DAG Management Shuffles. Reduce by map-side reducing, pre-partition (or bucketize) source data, maximize single shuffles, and reduce the amount of data sent.
- Prefer ReduceByKey with its fixed memory limit to GroupByKey, which provides
aggregations, windowing, and other functions but it has an unbounded memory limit. - Prefer TreeReduce, which does more work on the executors or partitions, to Reduce, which does all work on the driver.
- Leverage DataFrames rather than the lower-level RDD objects.
- Create ComplexTypes that encapsulate actions, such as “Top N”, various aggregations, or windowing operations.
What is SparkLens?
SparkLens is a profiling and performance prediction tool for Spark with built-in Spark Scheduler simulator. Its primary goal is to make it easy to understand the scalability limits of Spark applications. It helps in understanding how efficiently a
given Spark application uses the compute resources provided. Maybe your application will run faster with more executors, and maybe it won’t. SparkLens can answer this question by looking at a single run of your application.
Efficiency Statistics by SparkLens
The total Spark application wall clock time can be divided into time spent in driver and time spent in executors. When a Spark application spends too much time in the driver, it wastes the executors’ compute time. Executors can also waste compute time, because of lack of tasks or skew. And finally, critical path time is the minimum time that this application will take even if we give it infinite executors. Ideal application time is computed by assuming ideal partitioning (tasks == cores and no skew) of data in all stages of the application.
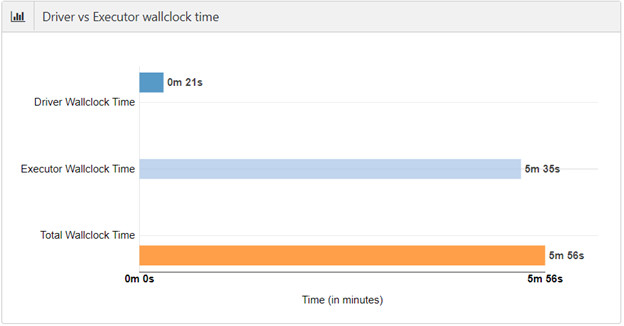
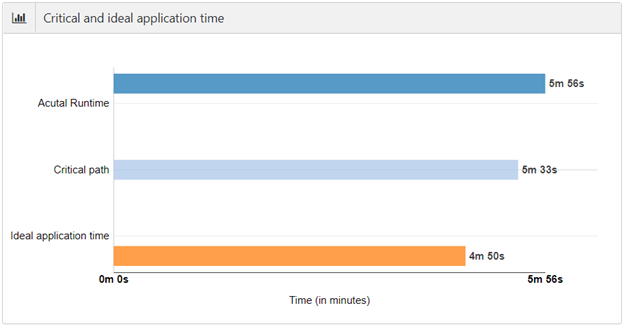
Simulation data by SparkLens
Using the fine-grained task level data and the relationship between stages, SparkLens can simulate how the application will behave when the number of executors is changed. Specifically, SparkLens will predict wall clock time and
cluster utilization. Note that cluster utilization is not cluster cpu utilization. It only means some task was scheduled on a core. The cpu utilization will further depend upon if the task is cpu bound or IO bound.
Ideal Executors Data by SparkLens
If autoscaling or dynamic allocation is enabled, we can see how many executors were available at any given time. SparkLens plots the executors used by different Spark jobs within the application, and what is the minimal number of executors (ideal) which could have finished the same work in the same amount of wall clock time.
The four important metrics printed per stage by SparkLens are:
• PRatio: Parallelism in the stage. The higher, the better.
• TaskSkew: Skew in the stage, specifically the ratio of largest to medial task times.
The lower, the better.
• StageSkew: Ratio of largest task to total stage time. The lower, the better.
• OIRatio: Output to input ratio in the stage.
This has been a short guide to point out the main concerns one should be aware of, when tuning a Spark application – most importantly, data serialization and memory tuning. We hope it was informative!
References: Microsoft Blog, SparkLens Documentation



2 Comments
Chrinstine · August 26, 2019 at 11:05 am
I couldn’t resist commenting. Well written! I
have been surfing on-line greater than 3 hours these days, but I
never discovered any interesting article like yours.
It is pretty worth enough for me. In my view, if all site owners and bloggers made just right content material as you did, the web shall be much more helpful than ever before.
This is a topic that’s close to my heart…
Many thanks! Exactly where are your contact details though?
http://foxnews.org
Sneha Mary Christall · August 28, 2019 at 11:00 am
Thank you for your kind words, you can contact us here: https://www.knowledgelens.com/contactUs.html