Introduction
Apache Spark has become the de facto unified engine for analytical workloads in the Big Data world. As we all know, Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. One of the main features Spark offers for speed is the ability to run computations in memory.
Spline is derived from the words Spark and Lineage. It is a tool which is used to visualize and track how the data changes over time. Spline provides a GUI where the user can view and analyze how the data transforms to give rise to the insights.
Pre-Requisites
- Microsoft Azure Subscription
- Microsoft Account
- Azure Databricks service
- Azure HDInsight/ Azure Virtual Machine
Spline on Databricks
Spline has broadly 2 components:
- A listener which analyzes the Spark commands, formulates the lineage data and store to a persistence.
- A GUI which reads the lineage data and helps users to visualize the data in the form of a graph.
We will be setting up the Spline on Databricks with the Spline listener active on the Databricks cluster, record the lineage data to Azure Cosmos. To view the visualization, we will set up Spline UI on an HDInsight cluster and connect to Cosmos DB to fetch the lineage data.
Step 1: Install dependencies on Databricks cluster
Install the following libraries on the Databricks cluster:
- spline-core version 0.3.9
- spline-core-spark-adapter-2.3 version 0.3.9
- spline-persistence-mongo version 0.3.9
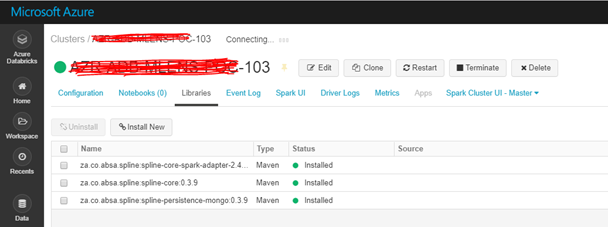
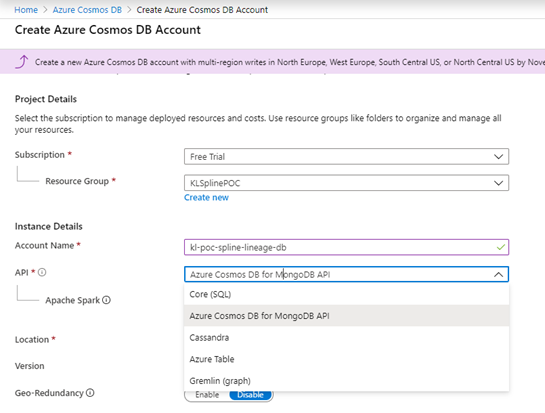
Step 2: Set up Azure Cosmos DB
- Create an Azure Cosmos DB with support for Mongo API
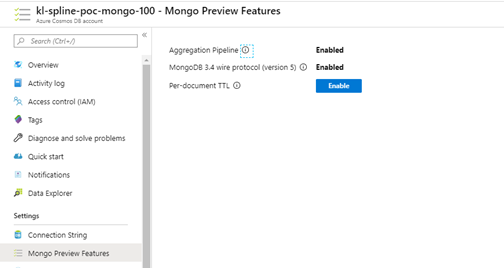
2. Enable Mongo Preview features as shown below:
Step 3: Enable Spline lineage tracking in Spark Job
%scala
System.setProperty("spline.mode","REQUIRED")
System.setProperty("spline.persistence.factory", "za.co.absa.spline.persistence.mongo.MongoPersistenceFactory")
System.setProperty("spline.mongodb.url", "mongodb://mongo_uri")
System.setProperty("spline.mongodb.name", "db_name")
spark._jvm.za.co.absa.spline.core.SparkLineageInitializer.enableLineageTracking(spark._jsparkSession)
Step 4: Run Spark Jobs
df = spark.read.format("csv"). option("header", "true").option("delimiter", "\t").option("inferSchema", "true").load("dbfs:/mnt/spline/test_file.csv")
df_2 = spark.read.format("csv").option("header", "true").option("delimiter", "\t").option("inferSchema", "true").load("dbfs:/mnt/spline/test_file2.csv")
df_a = df.alias("df_a")
df_b = df_2.alias("df_b")
df_3 = df_a.join(df_b, df_a.emp_id == df_b.emp_id).drop(df_b.emp_id).drop(df_b.name).drop(df_b.designation)
df_3.write.format("csv").mode(“overwrite”).option("header", "true").save("dbfs:/mnt/spline/output")Step 5: Launch Spline Web UI
First launch a Spark HDInsight with minimal configurations. Download the spline-web-0.3.9-exec-war.jar and run the following command:
java -jar spline-web-0.3.9-exec-war.jar -D”spline.mongodb.url=mongodb://xyz” -D"spline.mongodb.name=xyz" -jar ./spline-web-0.3.9-exec-war.jarHDInsight clusters provide access to the Apache Ambari web UI over the Internet, but some features require an SSH tunnel. Likewise, to view the Spline UI, we will have to create an SSH tunnel as described in the link #1 in the references.
Sample Spline GUI
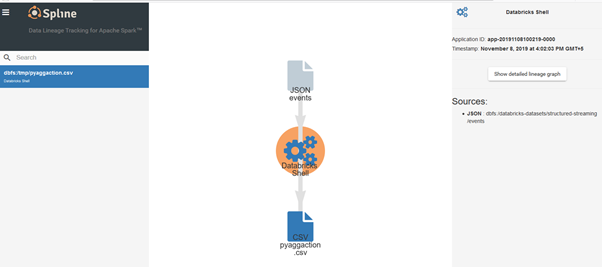
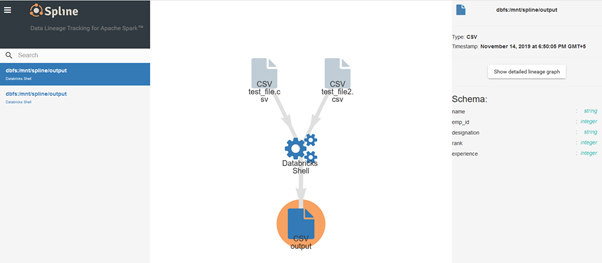
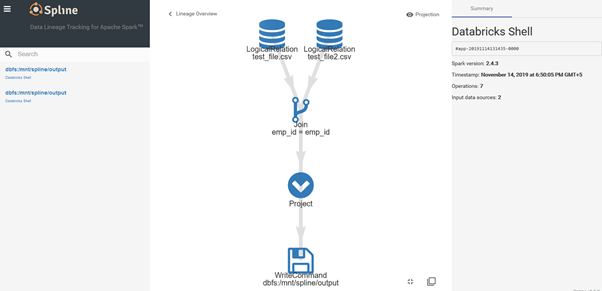
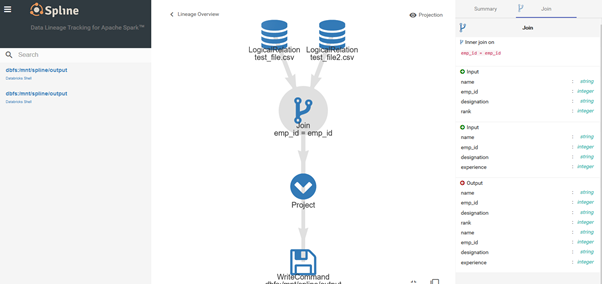
References:
- https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-linux-ambari-ssh-tunnel#prerequisites
- https://social.msdn.microsoft.com/Forums/azure/en-US/7b47b6a2-a888-4dd3-a226-183bfb59d96a/accessing-web-ui-of-custom-api-installed-in-hdinsight-hadoop-cluster?forum=hdinsight
- https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-linux-ambari-ssh-tunnel
- https://cloudarchitected.com/2019/04/data-lineage-in-azure-databricks-with-spline/#Spline_UI


